What are LLMs? Large Language Models Explained
Understand Large Language Models (LLMs): how they work, why they matter, and their impact on AI.
Large Language Models have changed artificial intelligence forever. They make advanced AI available to millions worldwide. ChatGPT became famous because natural language connects everyone to cutting-edge AI breakthroughs.
Yet most people don't understand how LLMs actually work. This guide takes you from zero knowledge to understanding these powerful systems. You'll learn the basic mechanisms that make LLMs tick.
We'll explore how these systems train and why they perform so well. By the end, you'll understand how LLMs function and discover tricks to get better results.
Summary
- Understanding AI Layers
- Machine Learning Basics
- Why Deep Learning is Needed
- How Neural Networks Work
- What are Large Language Models
- How LLMs Generate Text
- Training Phases Explained
- Real-World Applications
- Advanced Techniques
- Future of Language Models
- Frequently Asked Questions
- Conclusion
Understanding AI Layers
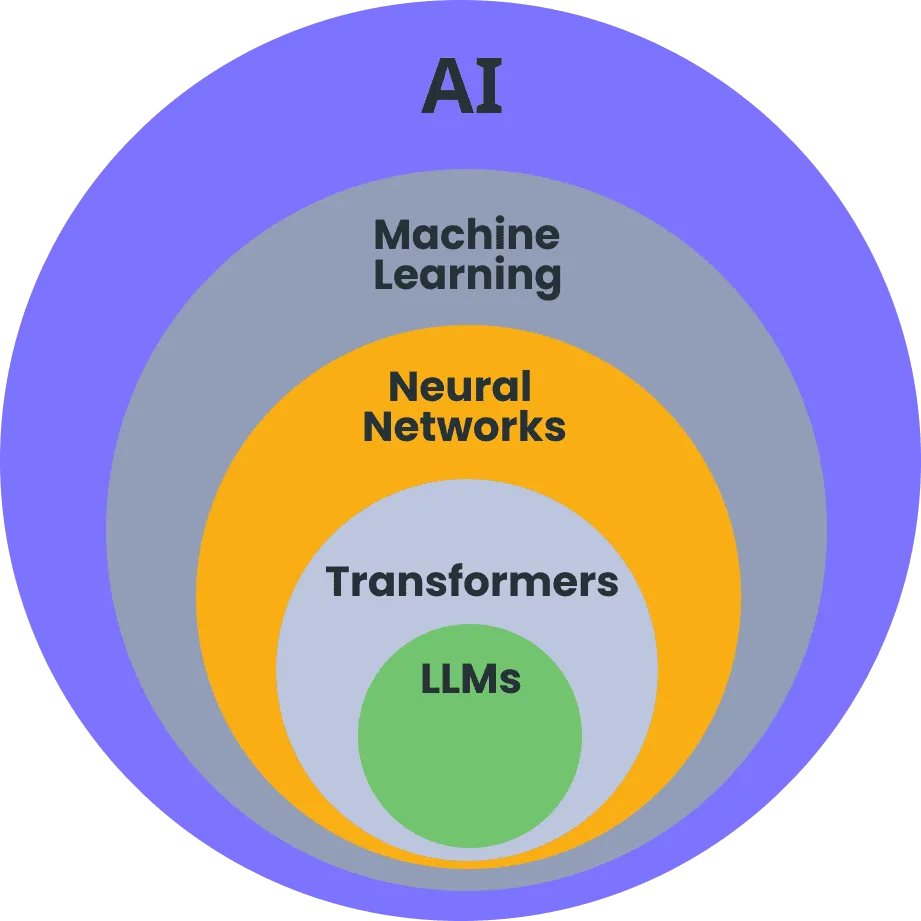
Artificial intelligence has different layers. Each layer builds on the previous one. Understanding these layers helps you see where LLMs fit.
Artificial Intelligence is the biggest category. It includes any system that shows intelligent behavior. This covers simple rule-based systems to complex reasoning machines.
Machine Learning sits inside AI. It focuses on finding patterns in data. Instead of programming rules, these systems learn from examples.
Deep Learning works within machine learning. It handles unstructured data like text, images, and audio. It uses artificial neural networks inspired by human brains.
Large Language Models are the most specialized layer. They focus only on understanding and generating human language. They power conversational AI systems like ChatGPT and Claude.
Machine Learning Basics
Machine learning finds patterns in data. It looks for relationships between inputs and outcomes. Think of it as teaching computers to make predictions from examples.
Let's say we want to tell reggaeton from R&B music. Reggaeton has lively beats and danceable rhythms. R&B has soulful vocals with different tempos.
With 20 songs and their tempo and energy levels, we can see patterns. High-energy, fast songs tend to be reggaeton. Lower-energy, slower songs are usually R&B.
A machine learning model learns this relationship during training. It finds the boundary that best separates these music types. Once trained, it can predict new songs using only tempo and energy.
- High tempo + High energy = Reggaeton
- Low tempo + Low energy = R&B
- Mixed signals = Uncertain prediction
Real problems are much more complex. They involve hundreds or thousands of input variables. The more complex the relationship, the more powerful the model needs to be.
Why Deep Learning is Needed
Traditional machine learning works well with structured data. But what about images or text? These need more powerful approaches.
Consider image classification. A small 224x224 image has over 150,000 pixels. Each pixel becomes an input variable. This creates a very high-dimensional problem.
The relationship between pixels and image content is extremely complex. Humans easily see cats, tigers, and foxes. Computers only see individual pixel values.
Text presents similar challenges. Converting words to numbers requires word embeddings. These capture meaning and grammar. A single sentence can create thousands of input variables.
The complexity grows with long documents, multiple languages, or contexts like sarcasm. Traditional models can't handle these complex relationships. This drove the development of deep learning and neural networks.
How Neural Networks Work
Neural networks are the most powerful machine learning models today. They can model complex relationships at massive scale. They're loosely inspired by human brains.
Neural networks have connected layers of artificial "neurons." Information flows through these layers. Each layer learns more complex features from the input data.
Think of neural networks as stacked pattern recognition layers. They're connected by functions that enable modeling complex relationships. The depth gives deep learning its name.
Modern neural networks can be enormous. ChatGPT has 176 billion parameters. That's more than the estimated 100 billion neurons in human brains.
The transformer architecture powers most modern LLMs. Its key innovation is the attention mechanism. This lets the model focus on relevant parts of input sequences.
This attention mimics how humans process information. We naturally focus on relevant details while ignoring distractions. This helps transformers handle long text sequences efficiently.
What are Large Language Models
Large Language Models are neural networks designed for human language. The "large" refers to their massive scale - over 1 billion parameters typically.
But what is a "language model"? It's a system trained to predict the next word in any sequence. This simple task requires understanding grammar, syntax, meaning, context, and world knowledge.
Language modeling learns patterns from vast text datasets. During training, the model sees millions of text sequences. It learns to predict what word comes next in each context.
This prediction is actually a massive classification problem. Instead of choosing between few categories, the model picks from about 50,000 possible words.
- Training data: Websites, books, research papers, code
- Task: Predict next word in sequence
- Vocabulary: ~50,000 words
- Parameters: 1+ billion connections
The training process is elegant. Text provides its own labels (the next word). No manual annotation needed. This enables training on unlimited data.
Modern LLMs train on diverse sources: websites, books, papers, code repositories. This teaches them language patterns and world knowledge.

How LLMs Generate Text
Once trained to predict the next word, LLMs can generate entire passages. They use a simple iterative process.
The model predicts one word and adds it to the input sequence. Then it predicts the next word based on this extended context. This continues word by word, building coherent text.
LLMs don't always choose the most likely word. They can sample from top predictions, adding creativity and variation. This explains why ChatGPT gives different responses when regenerated.
This generation process reveals why LLMs excel at various tasks. Whether completing sentences, answering questions, or writing code, they use the same next-word prediction mechanism.
The key insight is that everything before a word becomes context. As the model generates text, it builds working memory using previously generated content.
Training Phases Explained
Modern LLMs like ChatGPT undergo multiple training phases. Each phase serves a specific purpose.
Pre-training is the foundation phase. Models learn basic language understanding using massive text datasets. They learn grammar, syntax, and world knowledge through next-word prediction.
However, pre-trained models aren't ready for practical use. They excel at text completion but struggle with following instructions. Ask "What's your name?" and it might respond "What's your age?"
Instruction Fine-tuning addresses this limitation. The model learns from instruction-response pairs created by experts. This teaches it to follow commands and provide helpful answers.
Reinforcement Learning from Human Feedback (RLHF) is the final polish. Human evaluators rate model outputs. These preferences train the model to produce responses aligned with human values.
This multi-phase approach transforms raw text prediction into helpful, safe AI assistants. Each phase serves a crucial role in creating practical systems.
Real-World Applications
Understanding LLM training explains their impressive capabilities across diverse tasks. Let's explore some key applications and their underlying mechanisms.
Summarization works because humans create summaries in text. Research papers have abstracts, articles have conclusions. LLMs learned these patterns during pre-training, then refined them through instruction tuning.
Question Answering combines knowledge acquisition with conversational skills. Models learned facts from training data, then learned to present information conversationally through fine-tuning.
Code Generation succeeds because programming code appears throughout training data. LLMs learned programming patterns, syntax, and relationships between natural language and code implementations.
However, LLMs face challenges, particularly with hallucinations. They generate plausible but incorrect information because they learned to sound confident without inherent truth concepts.
Search-enhanced systems like Bing Chat address this by providing current context. They search for relevant information first, then ground responses in retrieved content.
For those wanting to master these capabilities, understanding prompt engineering strategies can significantly improve results with these systems.
Advanced Techniques
Large-scale LLMs show remarkable emerging abilities. These are capabilities that weren't explicitly trained but emerge from scale and diverse training.
Zero-shot Learning enables LLMs to tackle new tasks with just instructions. For example, asking to translate German using only words starting with "f" - a constraint never seen during training.
Few-shot Learning mirrors human learning by providing examples. Just as humans learn better with demonstrations, LLMs improve significantly when given 2-3 examples of desired task format.
Chain-of-Thought Reasoning unlocks complex problem-solving by encouraging step-by-step thinking. Adding "think step by step" to prompts can dramatically improve performance on multi-step problems.
This technique works because everything generated becomes context for subsequent predictions. By working through steps, the model builds "working memory" supporting sophisticated reasoning.
- Zero-shot: Instructions only
- Few-shot: Instructions + examples
- Chain-of-thought: Step-by-step reasoning
- In-context learning: Learning from conversation
These capabilities suggest large-scale language modeling learns compressed representations of world knowledge and reasoning patterns, not just statistical text patterns.
For developers interested in exploring these capabilities, resources like comprehensive AI tool guides provide valuable insights into this rapidly evolving field.
Future of Language Models
The rapid evolution of LLMs points toward exciting possibilities and important considerations for the coming years.
Enhanced Capabilities will likely include improved accuracy, reduced hallucinations, and better reasoning abilities. Current research focuses on making models more reliable and truthful while maintaining creativity.
Multimodal Integration is expanding beyond text to include audio, visual, and video inputs. Future models may seamlessly process and generate content across multiple media types.
Specialized Applications will emerge as businesses discover innovative uses. From automated customer service to sophisticated content creation, LLMs are transforming organizational operations.
Workplace Transformation seems inevitable as LLMs automate routine tasks while augmenting human capabilities. Rather than replacing humans, they're becoming powerful collaboration tools enhancing productivity.
The convergence of language understanding with other AI capabilities suggests movement toward more general artificial intelligence systems. While current LLMs excel at language tasks, future systems may demonstrate broader reasoning abilities.
For organizations wanting to explore AI agent capabilities, understanding how these systems integrate with LLM foundations becomes increasingly important.
Frequently Asked Questions
What exactly is a Large Language Model?
A Large Language Model (LLM) is a neural network trained to predict the next word in text sequences, enabling it to understand and generate human language.
How do LLMs generate text responses?
LLMs generate text by predicting one word at a time, using previous words as context for the next prediction in an iterative process.
What training phases do modern LLMs go through?
Modern LLMs undergo three phases: pre-training on massive text data, instruction fine-tuning, and reinforcement learning from human feedback.
Why do LLMs sometimes give wrong information?
LLMs can hallucinate because they're trained to sound confident but don't have inherent concepts of truth or uncertainty about their knowledge.
What makes neural networks so powerful for language?
Neural networks can model complex relationships through multiple layers of pattern recognition, with attention mechanisms focusing on relevant information.
Conclusion
Large Language Models represent a remarkable achievement in artificial intelligence. They transform decades of research into practical tools that millions use daily. From next-word prediction to sophisticated reasoning, these systems demonstrate capabilities that continue surprising

Answer Engine Optimization (AEO): Complete Guide 2026

How to Create Effective Prompts for LLM Text Generation

What is GEO? Generative Engine Optimization Guide

AI Video Prompts That Work: Complete Guide for 2026
